
Iceberg + Spark + Trino : une pile de données open source moderne pour la blockchain
1.Le défi de la pile de données blockchain moderne
Une startup d’indexation blockchain moderne peut être confrontée à plusieurs défis, notamment :
- Des quantités massives de données. À mesure que la quantité de données sur la blockchain augmente, l’index de données devra évoluer pour gérer la charge accrue et fournir un accès efficace aux données. Par conséquent, cela entraîne des coûts de stockage plus élevés, un calcul de mesures lent et une charge accrue sur le serveur de base de données.
- Pipeline de traitement de données complexe. La technologie Blockchain est complexe, et la construction d’un index de données complet et fiable nécessite une compréhension approfondie des structures de données et des algorithmes sous-jacents. La diversité des implémentations de blockchain en hérite. Compte tenu d’exemples spécifiques, les NFT dans Ethereum sont généralement créés dans des contrats intelligents suivant les formats ERC721 et ERC1155. En revanche, la mise en œuvre de ceux sur Polkadot, par exemple, est généralement construite directement dans l’environnement d’exécution de la blockchain. Ceux-ci doivent être considérés comme des NFT et doivent être enregistrés en tant que tels.
- Capacités d’intégration. Pour fournir une valeur maximale aux utilisateurs, une solution d’indexation blockchain peut avoir besoin d’intégrer son index de données à d’autres systèmes, tels que des plateformes d’analyse ou des API. Ceci est difficile et nécessite des efforts importants dans la conception de l’architecture.
À mesure que la technologie blockchain s’est généralisée, la quantité de données stockées sur la blockchain a augmenté. En effet, de plus en plus de personnes utilisent la technologie et chaque transaction ajoute de nouvelles données à la blockchain. De plus, la technologie blockchain a évolué à partir de simples applications de transfert d’argent, telles que celles impliquant l’utilisation de Bitcoin, vers des applications plus complexes impliquant la mise en œuvre d’une logique métier dans des contrats intelligents. Ces contrats intelligents peuvent générer de grandes quantités de données, contribuant à la complexité et à la taille accrues de la blockchain. Au fil du temps, cela a conduit à une blockchain plus grande et plus complexe.
Dans cet article, nous passons en revue l’évolution de l’architecture technologique de Footprint Analytics par étapes en tant qu’étude de cas pour explorer comment la pile technologique Iceberg-Trino relève les défis des données en chaîne.
Footprint Analytics a indexé environ 22 données de blockchain publiques et 17 marchés NFT, 1900 projets GameFi et plus de 100 000 collections NFT dans une couche de données d’abstraction sémantique. C’est la solution d’entrepôt de données blockchain la plus complète au monde.
Indépendamment des données de la blockchain, qui comprennent plus de 20 milliards de lignes d’enregistrements de transactions financières, que les analystes de données interrogent fréquemment. c’est différent des journaux d’entrée dans les entrepôts de données traditionnels.
Nous avons connu 3 mises à niveau majeures au cours des derniers mois pour répondre aux exigences commerciales croissantes :
2. Architecture 1.0 BigQuery
Au début de Footprint Analytics, nous utilisions Google BigQuery comme moteur de stockage et de requête. BigQuery est un excellent produit. Il est incroyablement rapide, facile à utiliser et fournit une puissance arithmétique dynamique et une syntaxe UDF flexible qui nous aide à faire le travail rapidement.
Cependant, BigQuery a également plusieurs problèmes.
- Les données ne sont pas compressées, ce qui entraîne des coûts élevés, en particulier lors du stockage des données brutes de plus de 22 chaînes de blocs de Footprint Analytics.
- Simultanéité insuffisante : Bigquery n’accepte que 100 requêtes simultanées, ce qui n’est pas adapté aux scénarios de simultanéité élevée pour Footprint Analytics lorsqu’il sert de nombreux analystes et utilisateurs.
- Verrouillez-vous avec Google BigQuery, qui est un produit à source fermée。
Nous avons donc décidé d’explorer d’autres architectures alternatives.
3. Architecture 2.0 OLAP
Nous étions très intéressés par certains des produits OLAP qui étaient devenus très populaires. L’avantage le plus attrayant d’OLAP est son temps de réponse aux requêtes, qui prend généralement moins de secondes pour renvoyer les résultats des requêtes pour des quantités massives de données, et il peut également prendre en charge des milliers de requêtes simultanées.
Nous avons choisi l’une des meilleures bases de données OLAP, Doris, pour l’essayer. Ce moteur fonctionne bien. Cependant, à un moment donné, nous avons rapidement rencontré d’autres problèmes :
- Les types de données tels que Array ou JSON ne sont pas encore pris en charge (novembre 2022). Les tableaux sont un type de données courant dans certaines blockchains. Par exemple, le champ topic dans les journaux evm. L’impossibilité de calculer sur Array affecte directement notre capacité à calculer de nombreuses métriques commerciales.
- Prise en charge limitée de DBT et des instructions de fusion. Ce sont des exigences courantes pour les ingénieurs de données pour les scénarios ETL/ELT où nous devons mettre à jour certaines données nouvellement indexées.
Cela étant dit, nous ne pouvions pas utiliser Doris pour l’ensemble de notre pipeline de données en production, nous avons donc essayé d’utiliser Doris comme base de données OLAP pour résoudre une partie de notre problème dans le pipeline de production de données, agissant comme un moteur de requête et fournissant des informations rapides et hautement capacités de requêtes simultanées.
Malheureusement, nous n’avons pas pu remplacer Bigquery par Doris, nous avons donc dû synchroniser périodiquement les données de Bigquery vers Doris en l’utilisant comme moteur de requête. Ce processus de synchronisation présentait plusieurs problèmes, dont l’un était que les écritures de mise à jour s’empilaient rapidement lorsque le moteur OLAP était occupé à répondre aux requêtes des clients frontaux. Par la suite, la vitesse du processus d’écriture a été affectée et la synchronisation a pris beaucoup plus de temps et est même parfois devenue impossible à terminer.
Nous avons réalisé que l’OLAP pouvait résoudre plusieurs problèmes auxquels nous sommes confrontés et ne pouvait pas devenir la solution clé en main de Footprint Analytics, en particulier pour le pipeline de traitement des données. Notre problème est plus grand et plus complexe, et nous pourrions dire qu’OLAP en tant que moteur de requête seul ne nous suffisait pas.
4. Architecture 3.0 Iceberg + Trino
Bienvenue dans l’architecture Footprint Analytics 3.0, une refonte complète de l’architecture sous-jacente. Nous avons entièrement repensé l’architecture pour séparer le stockage, le calcul et l’interrogation des données en trois éléments différents. Tirer les leçons des deux architectures précédentes de Footprint Analytics et apprendre de l’expérience d’autres projets Big Data réussis comme Uber, Netflix et Databricks.
4.1. Présentation du lac de données
Nous avons d’abord porté notre attention sur le lac de données, un nouveau type de stockage de données pour les données structurées et non structurées. Le lac de données est parfait pour le stockage de données en chaîne, car les formats de données en chaîne varient largement, des données brutes non structurées aux données d’abstraction structurées pour lesquelles Footprint Analytics est bien connu. Nous nous attendions à utiliser le lac de données pour résoudre le problème du stockage des données, et idéalement, il prendrait également en charge les moteurs de calcul traditionnels tels que Spark et Flink, de sorte qu’il ne serait pas difficile de s’intégrer à différents types de moteurs de traitement à mesure que Footprint Analytics évolue. .
Iceberg s’intègre très bien avec Spark, Flink, Trino et d’autres moteurs de calcul, et nous pouvons choisir le calcul le plus approprié pour chacune de nos métriques. Par exemple:
- Pour ceux qui ont besoin d’une logique de calcul complexe, Spark sera le choix.
- Flink pour le calcul en temps réel.
- Pour les tâches ETL simples pouvant être effectuées à l’aide de SQL, nous utilisons Trino.
4.2. Moteur de requête
Iceberg résolvant les problèmes de stockage et de calcul, nous avons dû réfléchir au choix d’un moteur de requête. Il n’y a pas beaucoup d’options disponibles. Les alternatives que nous avons envisagées étaient
- Trino : moteur de requête SQL
- Presto : moteur de requête SQL
- Kyuubi : Spark SQL sans serveur
La chose la plus importante que nous avons considérée avant d’aller plus loin était que le futur moteur de requête devait être compatible avec notre architecture actuelle.
- Pour prendre en charge BigQuery en tant que source de données
- Pour supporter DBT, sur lequel nous nous appuyons pour produire de nombreuses métriques
- Pour prendre en charge la métabase de l’outil BI
Sur la base de ce qui précède, nous avons choisi Trino, qui offre un très bon support pour Iceberg et l’équipe a été si réactive que nous avons signalé un bogue, qui a été corrigé le lendemain et publié dans la dernière version la semaine suivante. C’était le meilleur choix pour l’équipe Footprint, qui exige également une grande réactivité de mise en œuvre.
4.3. Test de performance
Une fois que nous avons décidé de notre direction, nous avons fait un test de performance sur la combinaison Trino + Iceberg pour voir si elle pouvait répondre à nos besoins et à notre grande surprise, les requêtes ont été incroyablement rapides.
Sachant que Presto + Hive est le pire comparateur depuis des années dans tout le battage médiatique OLAP, la combinaison de Trino + Iceberg nous a complètement époustouflé.
Voici les résultats de nos tests.
cas 1 : rejoindre un grand ensemble de données
Une table de 800 Go1 rejoint une autre table de 50 Go2 et effectue des calculs commerciaux complexes
case2 : utilisez une grande table unique pour effectuer une requête distincte
Test sql : sélectionnez distinct (adresse) dans le groupe de tables par jour
La combinaison Trino+Iceberg est environ 3 fois plus rapide que Doris dans la même configuration.
De plus, il y a une autre surprise car Iceberg peut utiliser des formats de données tels que Parquet, ORC, etc., qui vont compresser et stocker les données. Le stockage de table d’Iceberg ne prend qu’environ 1/5 de l’espace des autres entrepôts de données. La taille de stockage de la même table dans les trois bases de données est la suivante :
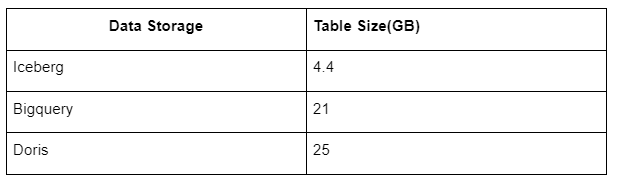
Remarque : Les tests ci-dessus sont des exemples que nous avons rencontrés en production réelle et sont à titre indicatif uniquement.
4.4. Effet de mise à niveau
Les rapports de test de performances nous ont donné suffisamment de performances pour qu’il ait fallu environ 2 mois à notre équipe pour terminer la migration, et voici un schéma de notre architecture après la mise à niveau.
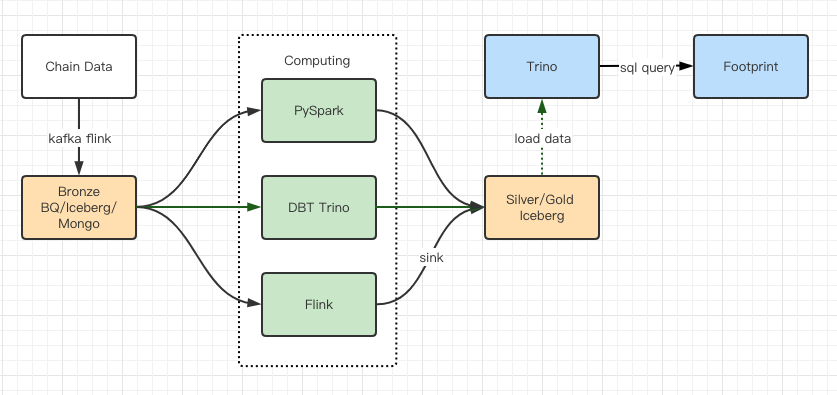
- Plusieurs moteurs informatiques correspondent à nos différents besoins.
- Trino prend en charge DBT et peut interroger Iceberg directement, nous n’avons donc plus à nous soucier de la synchronisation des données.
- Les performances étonnantes de Trino + Iceberg nous permettent d’ouvrir toutes les données Bronze (données brutes) à nos utilisateurs.
5. Résumé
Depuis son lancement en août 2021, l’équipe Footprint Analytics a réalisé trois mises à niveau architecturales en moins d’un an et demi, grâce à sa forte volonté et sa détermination à apporter les avantages de la meilleure technologie de base de données à ses utilisateurs de crypto et une exécution solide sur la mise en œuvre et mise à niveau de son infrastructure et de son architecture sous-jacentes.
La mise à niveau 3.0 de l’architecture Footprint Analytics a offert une nouvelle expérience à ses utilisateurs, permettant aux utilisateurs d’horizons différents d’obtenir des informations sur des utilisations et des applications plus diverses :
- Construit avec l’outil Metabase BI, Footprint permet aux analystes d’accéder aux données décodées en chaîne, d’explorer avec une totale liberté de choix d’outils (sans code ou en dur), d’interroger l’historique complet et de contre-interroger les ensembles de données, pour obtenir des informations sur pas le temps.
- Intégrez les données en chaîne et hors chaîne à l’analyse sur web2 + web3 ;
- En créant/interrogeant des métriques au-dessus de l’abstraction métier de Footprint, les analystes ou les développeurs gagnent du temps sur 80 % du travail répétitif de traitement des données et se concentrent sur des métriques, des recherches et des solutions produit significatives en fonction de leur activité.
- Expérience transparente des appels Footprint Web aux API REST, tous basés sur SQL
- Alertes en temps réel et notifications exploitables sur les signaux clés pour soutenir les décisions d’investissement
Le post Iceberg + Spark + Trino : une pile de données open source moderne pour la blockchain est apparue en premier sur CryptoSlate.